How to use Onesait lookup processor
- DevPortal Editor (Unlicensed)
- doc_enterprise
EN | ES
Description
The Onesait processor stage of Dataflow manages the receieved records and joins data from other ontologies.
How to use it
Importing to the pipeline
To add it to the pipeline, search for Onesait in the stages palette like so.
Drag and drop it to the panel or just click on it.
Once imported, it can be configured to achieve different beheaviours depending on the case.
Available configuration tabs
General
This tab shows general information and an option to show the event generator point on the stage.

Checking the "Produce Events" option the stage shows another point to make usage of the events.
The events triggered are:
- Document found
- Which sends the found records in a list (records-found) for each bulk
- Document not found
- Which sends the not found records in a list (records-not-found) for each bulk
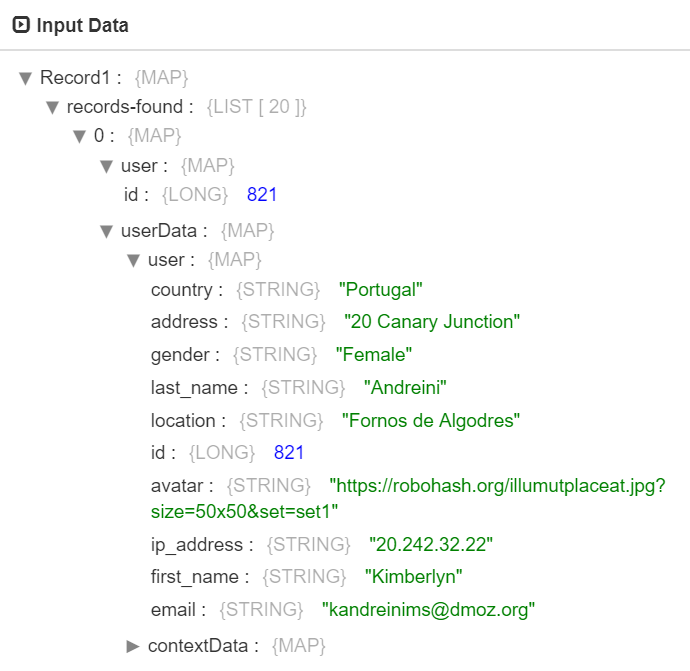
For example, records-found:
Source
This tab shows a form to fill with the Digital Broker information of the Onesait platform.

Additionally, it can be configured the maximum characters to make SQL query as it uses the http GET method.
- Max GET characters: by default it uses 10000 characters to split the queries in chunks, but if the server support less or more it should be set applying the server configuration. It may be useful also if the server returns timeouts doing complex queries by splitting them in simpler ones.
Query

- Query type: You can choose whether to do a query with these components or do it in a customised way with the sql mode.

- Select: You select the fields you want to return in the query.
- Where: Fields to use to match the document in the ontology.
- Record field: The field of the record to get the value from.
- Column name: The property path in the data source.
- Optional path: If the returned document from the ontology lacks of root paths (this coud be caused when using the column selector), the path to search the value may be different from the column name field and the match won't be done. This path can be set on this field separated by dots (.), otherwise leave blank.
Configuration
This tab shows the main configuration of the stage.
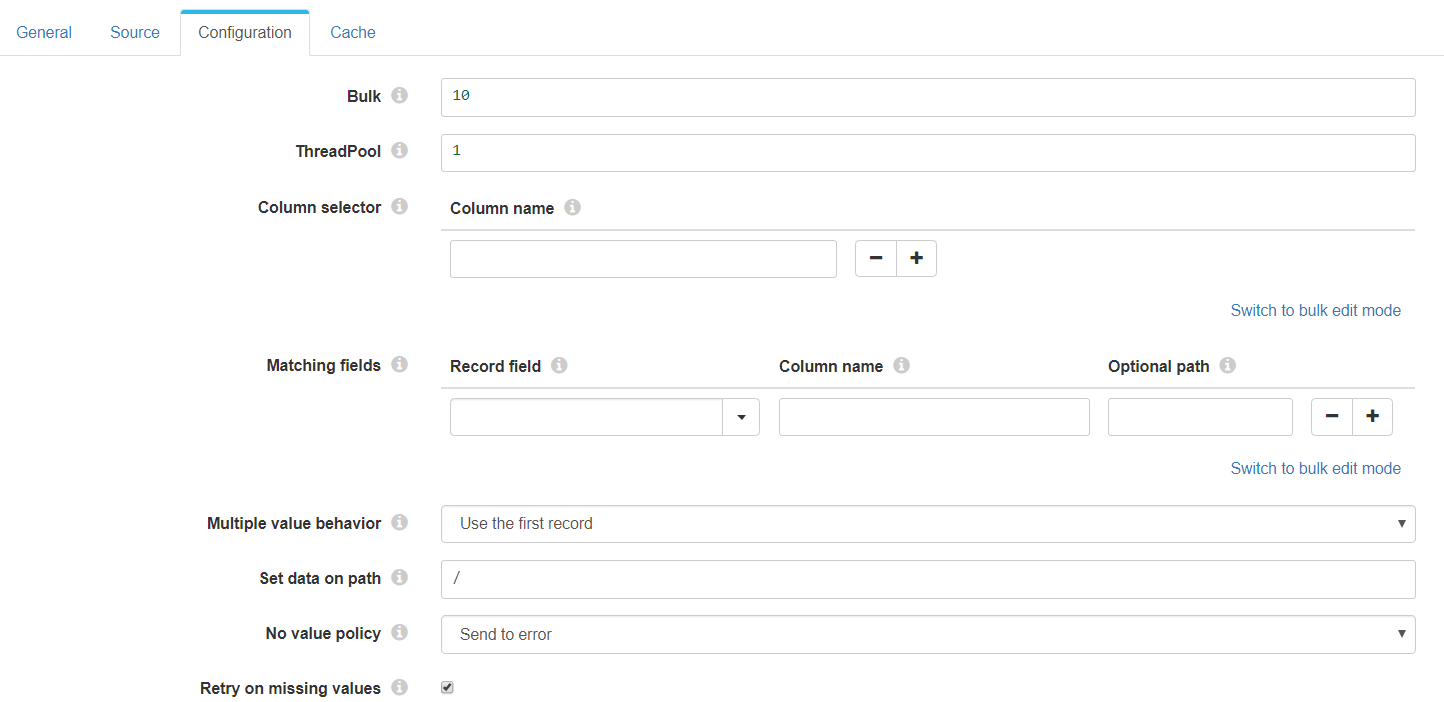
- ThreadPool: Number of threads to create.
- Multiple value behaviour. If several documents are found by the matching fields.
- Use the first record: It just uses the first document fetched from the data source.
- Create a list in the record: Creates a list in the record with all the documents fetched from the ontology.
- Generate multiple records: Generates new records as the number of the documents found in the data source.
- Set data on path: Sets the data on the specified path in streamsets format. Eg. /userData
- No value policy: If no data is found with the matching data pass on, an action is triggered.
Performance tip for fetching data from the ontolgy
Use just one unique index (matching field in the node configuration) if possible in ontologies (eg. unique id). This way the lookup will group better the queries (using WHERE IN) to the ontology and use less resources, otherwise, it will group the queries too, but less performant (using AND and OR).
Cache
This tabs specifies the cache settings. Enabled by default to limit queries to the ontology and thus, speeding up the process and reducing the load on the server.

- Use local cache: Enables or disables the local cache to store data retreived from the data source to limit the queries. Enabled by default.
- Limit cache entries: Cache evition by number of entries. Disabled by default.
- Max. entries: Limits the number of entries in the memory cache if the option is set.
- Cache expiration: Cache evition by time. Disabled by default.
- Expiration time: Time value
- Time unit: Time unit from nanoseconds to days.
- Expiration policy: How entries expires in time.
- After last access to the entry.
- After last write of the entry.
Retry: Do not wait for the cache to expire before retrying if no document has been found.
Initial cache population: Fills the cache with entity data.
Example 1
Let's say we are receiving records with an unique id refering to some data stored in an ontolgy in the Onesait platform. In this example, we are getting an object (user) with a property id.
Firstly we have to configure the source tab using the configuration of our server. Then we would configure the node with the options showed below.
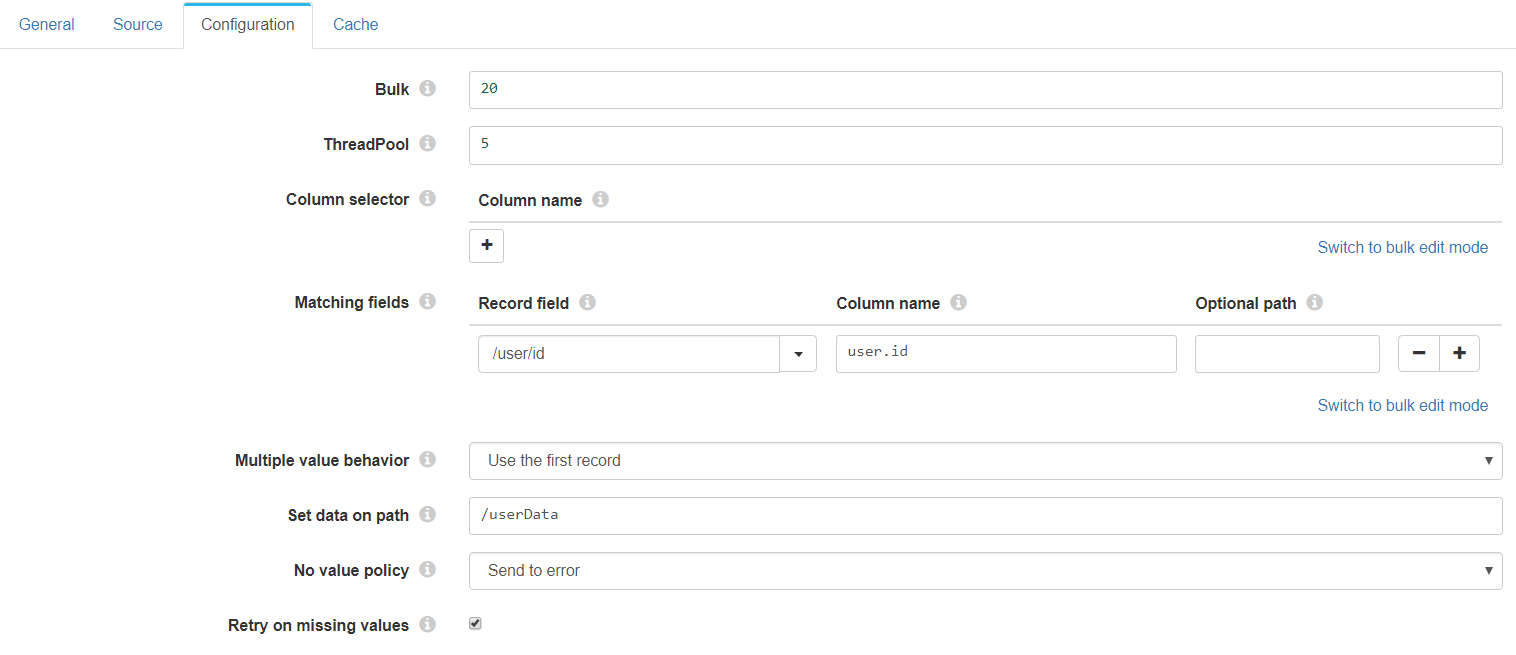
This configuration will
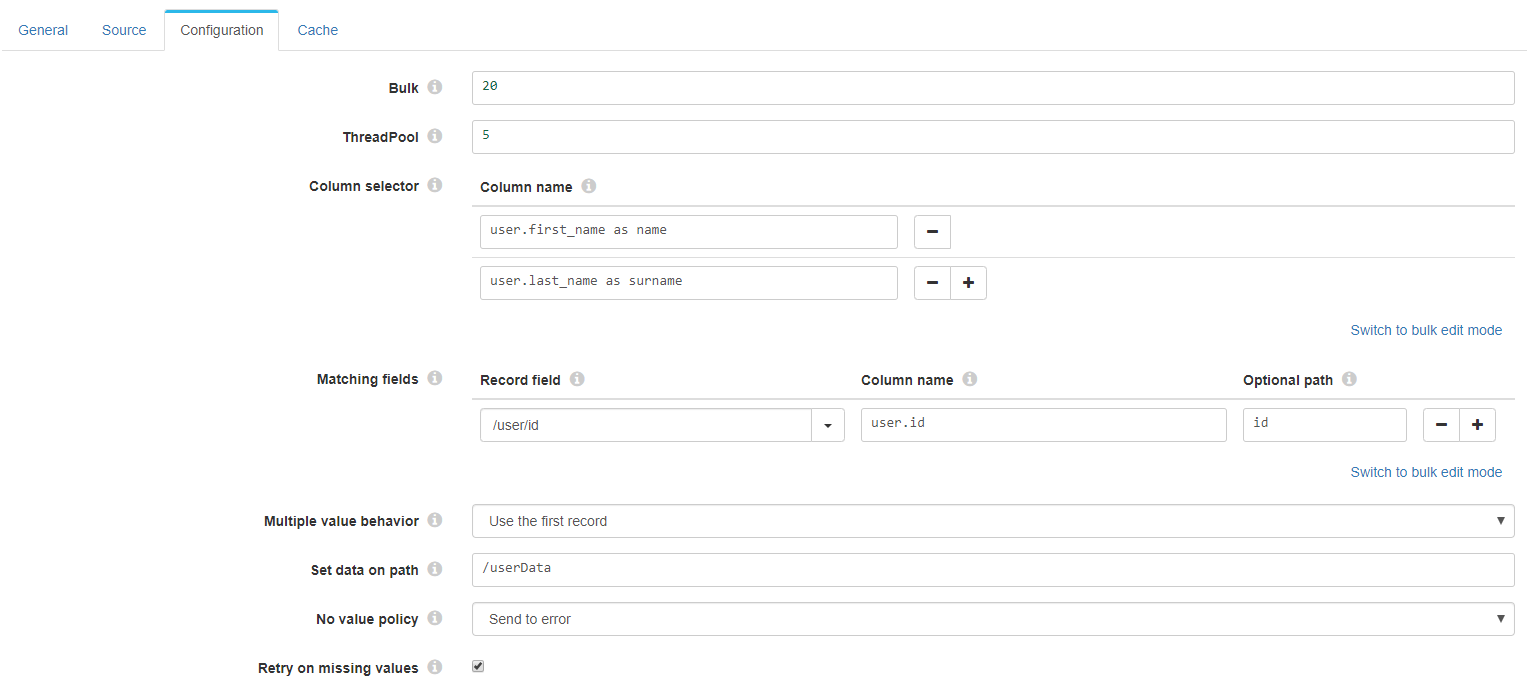
- Group the records in bulks of 20 and generate 5 threads.
- Get all the possible information from the ontolgy, as we have not configured any column selector, and thus sending an * in the select query.
- Match the information of the record getting the value from the path /user/id and and looking for it in the ontology in the path user.id
- Use the first coincidence if more are found, due to the multiple value behavior option selected.
- Set the data in the path /userData
- If no document is found send to error
- Keep retrying the query to the ontology if no document is found
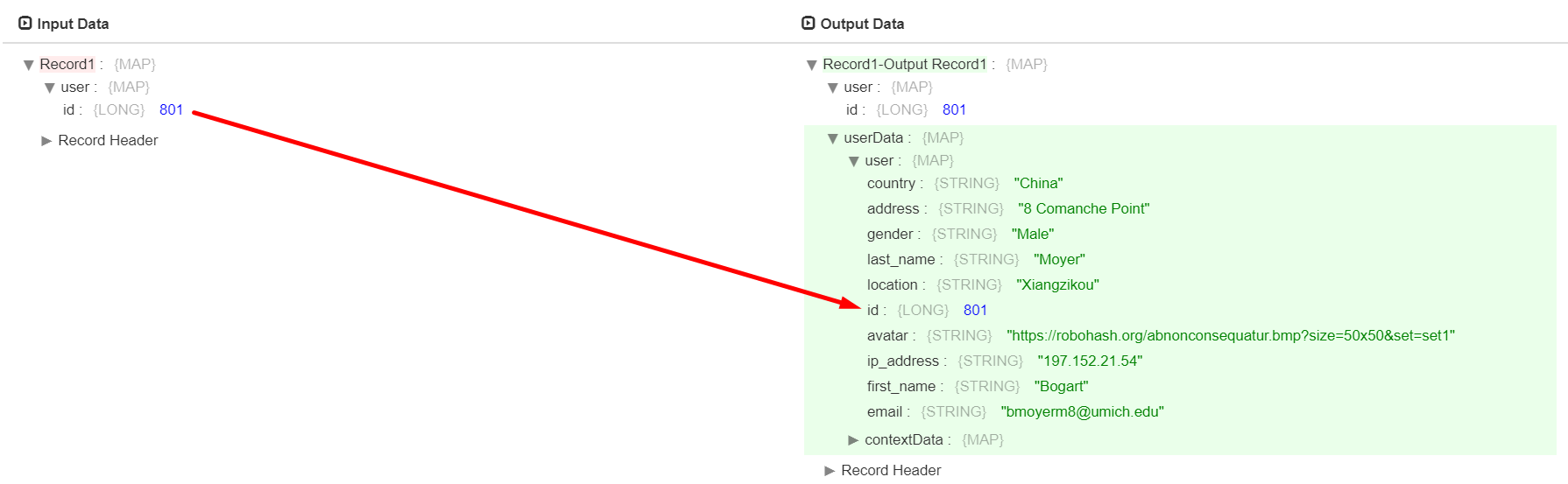
and produce the following output.
Example 2
If we just need some info we could select them using the column selector.
But in this case, the data returned by the query won't contain the root node "user" becase we have selected just two properties from the document,
{
"name" : "Bogart",
"surname" : "Moyer",
"id" : 801
}
And it will be necessary to set the optional path to id. Otherwise the data won't be matched and the returned data will be

The data returned by this configuration if the optional path is set

Example 3 - airportsdata
Using the ontology airportsdata we can create a good example on how to use the lookup.
The final goal is to get the latitude and longitude from an airport using its name. So let's get into it.

Stages involved
- Onesait Origin - To get the data from the airports
- Expression evaluator - To move the name property to the root of the record
- Field remover - To remove the rest of the data
- Lookup - To retrieve the selected data from the ontology using the name property
- Trash - Final result
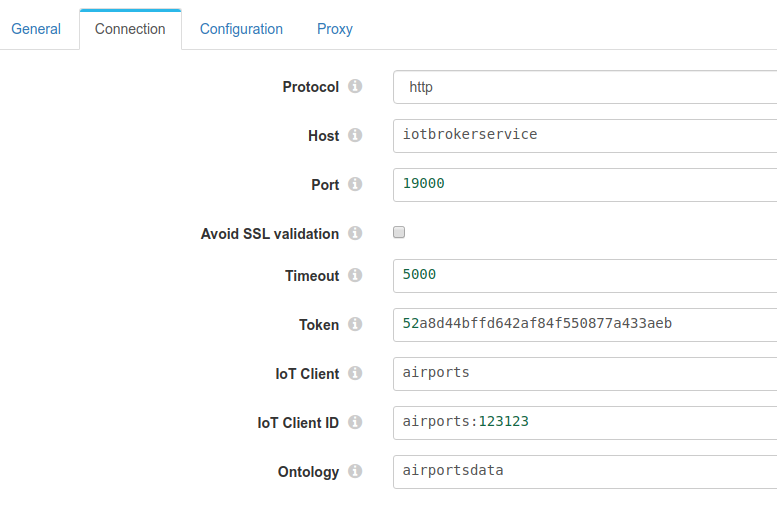
Origin
The sql to send in the request
select * from airportsdata as c offset ${offset} limit ${batch}
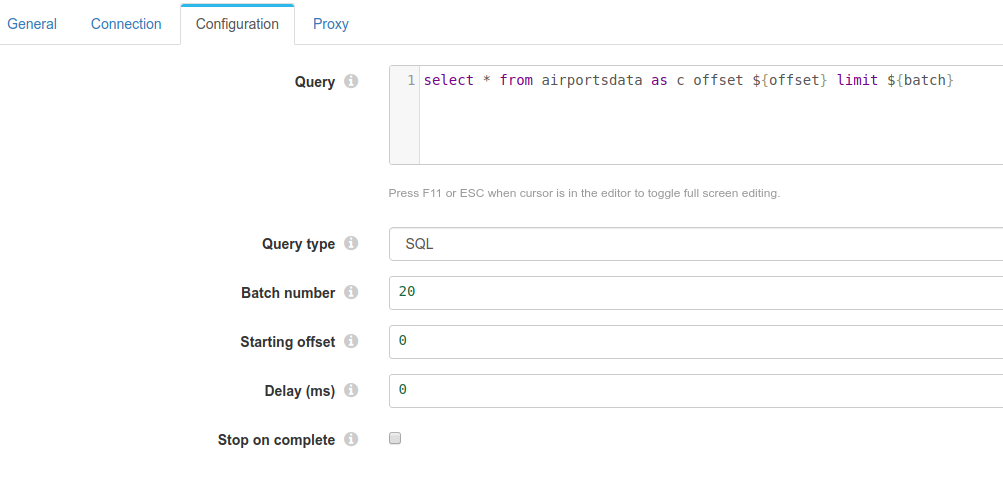
Note: We could have just selected the name property, but this is to recreate a possible scenario.
Expression evaluator
Move the property to the root of the record.

Field expression: ${record:value('/airportsdata/name')}
Field remover
Keep the name property in the root of the Record.

Lookup
Connection details.
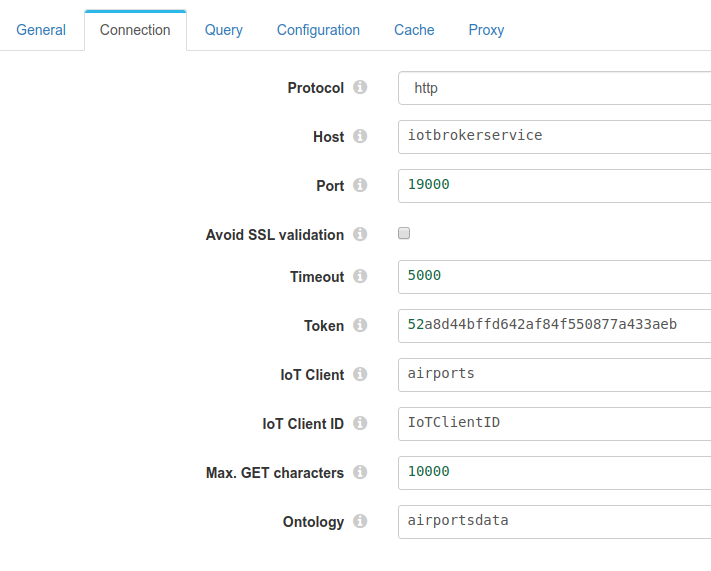
Query details
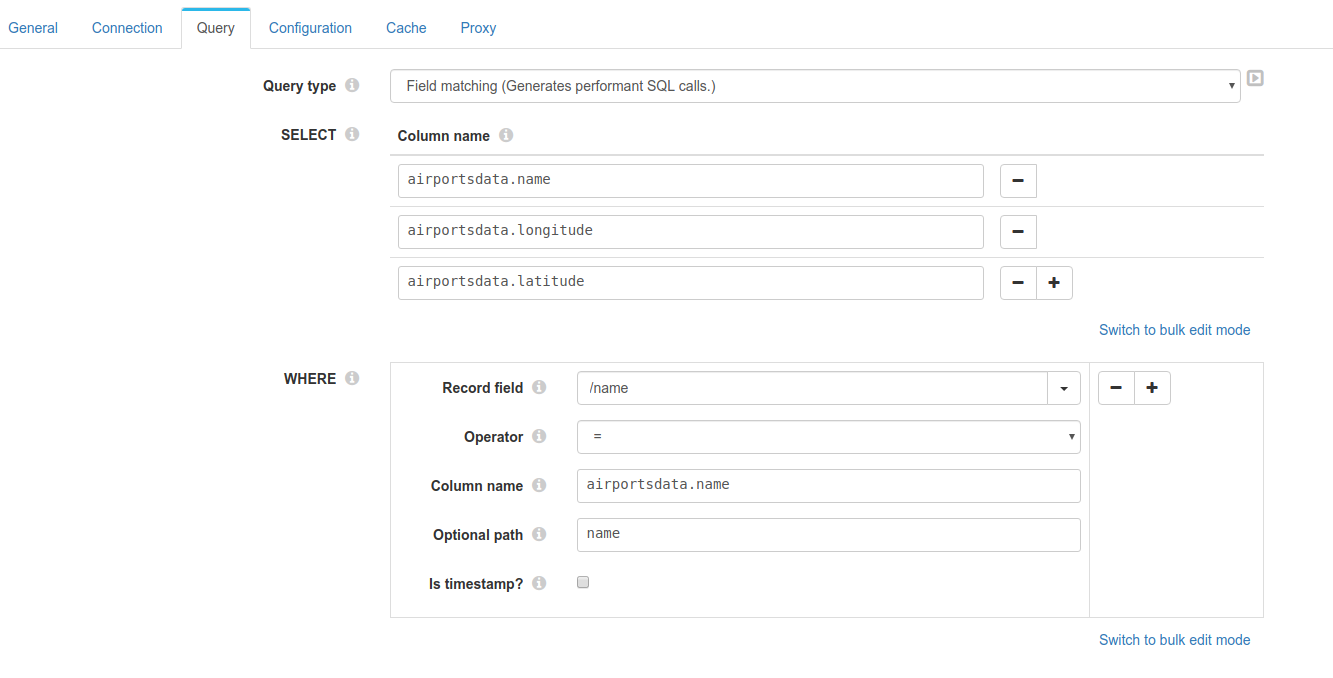
The query generated will be
SELECT airportsdata.name,airportsdata.longitude,airportsdata.latitude /* SELECT Column name */
FROM airportsdata AS c
WHERE airportsdata.name /* WHERE Column name */ IN ('A 511 Airport','A Coru_a Airport','Aachen-Merzbr_ck Airport','Aalborg Airport','Aalen-Heidenheim/Elchingen Airport','Aarhus Airport','Aasiaat Airport','Aba Tenna Dejazmach Yilma International Airport','Abaco I Walker C Airport','Abadan Airport')
Which will return
[{"name":"A 511 Airport","longitude":"127.03099822998047","latitude":"36.96220016479492"},{"name":"A Coru_a Airport","longitude":"-8.377260208129883","latitude":"43.302101135253906"},{"name":"Aachen-Merzbr_ck Airport","longitude":"6.186388969421387","latitude":"50.823055267333984"},{"name":"Aalborg Airport","longitude":"9.84924316406","latitude":"57.0927589138"},{"name":"Aalen-Heidenheim/Elchingen Airport","longitude":"10.264721870422363","latitude":"48.77777862548828"},{"name":"Aarhus Airport","longitude":"10.619000434899998","latitude":"56.2999992371"},{"name":"Aasiaat Airport","longitude":"-52.7846984863","latitude":"68.7218017578"},{"name":"Aba Tenna Dejazmach Yilma International Airport","longitude":"41.85419845581055","latitude":"9.624699592590332"},{"name":"Abaco I Walker C Airport","longitude":"-78.39969635009766","latitude":"27.266700744628906"},{"name":"Abadan Airport","longitude":"48.2282981873","latitude":"30.371099472"}]
Notice why the Optional path is used in this example. The column name is airportsdata.name but the data returned lacks of root node airportsdata so to be able to match the document, the optional path is set to look into that json path (name) on the root.
The result of the lookup adding the data to the record.
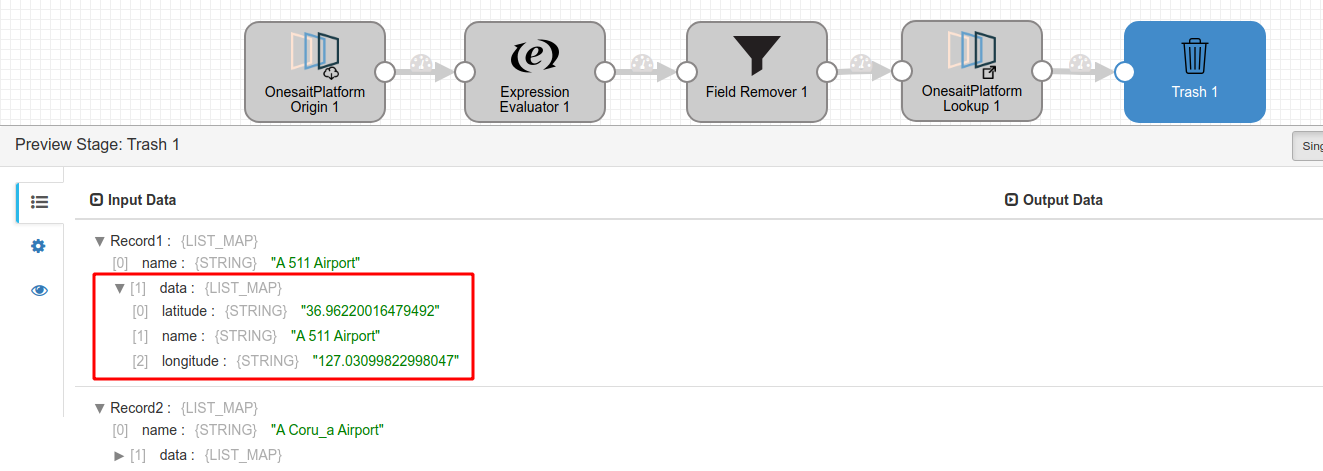
You can get the example in the link below, but you need to edit the clients information.