Features | Open Source | Releases | Docs | Try us free | Blog | Product
Ontologies historization: deleting old instances and exporting to files
Introduction
There is a new functionality allowing you to export and delete old data from an ontology from the real-time databases. In this tutorial, we are going to explain how to configure an ontology to achieve it, and how to consult the files that this process creates.
Ontology configuration
Create/Update an ontology, and go to the Advanced Settings tab.
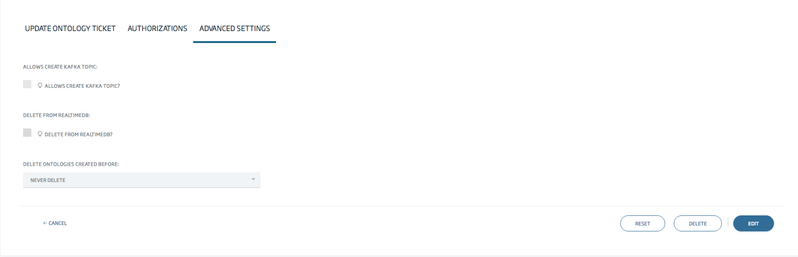
As you can see, there is an option called Delete from realtimedb. If you check it, you will have to choose a time threshold (1 month by default) from which the data will be deleted.
A new checkbox will also pop up when checking the previous delete option:
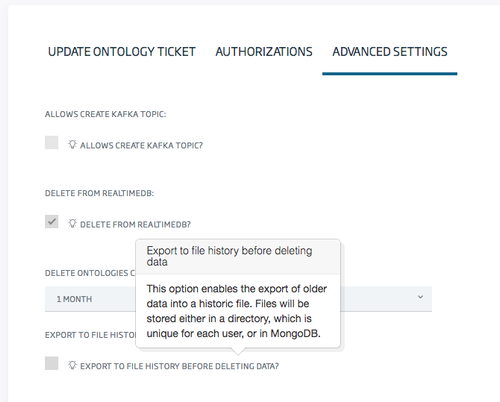
Checking this option will export the data prior to delete.
Lastly, if checked, you will have to choose between two storage modes: GridFS (Mongo) and Directory file.
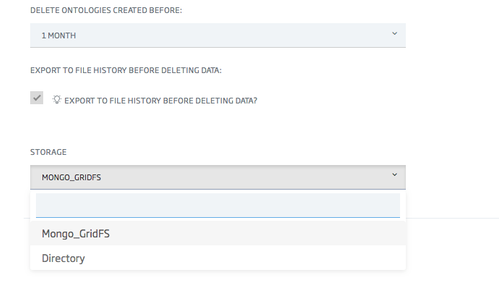
We strongly recommend the use of GridFS, as it uses a distributed storage system, while directory files does not.
Retrieving exported files
Whether you selected GridFS or Directory as storage, you will be able to access (CRUD) those exported files, either through the binary repository page in controlpanel or using the REST service exposed for the binary repository.
1. Controlpanel binary files management
If you go to the path /controlpanel/files/list, you will see a list of files belonging to your user.
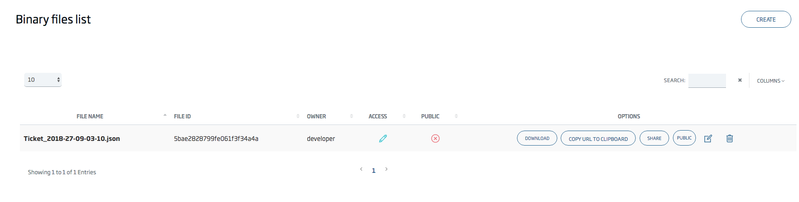
Those files that are named with the following pattern: (ontology)_(timestamp).json, will become exported files created by the deletion process.
As explained in this tutorial, binary files can be shared with users of the platform, and can also be made public. If the file is public, you can access it (read only) without any kind of authentication, from anywhere, for example from a notebook (example at the end of this tutorial).
The copy url to clipboard copies the external url for accessing the file.
2. REST API
Explained in this post.
Notebook example
In this example, we will illustrate how we can retrieve an exported file within a notebook and load its data.
1. The file is public
If the file is public, you do not need any kind of authentication, you just need to make a simple wget request:
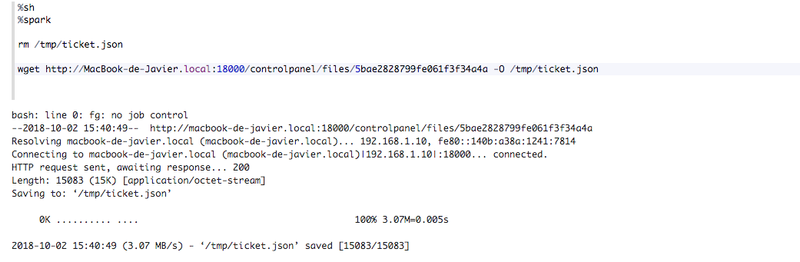
If the file is not public, this will give a 403 response:
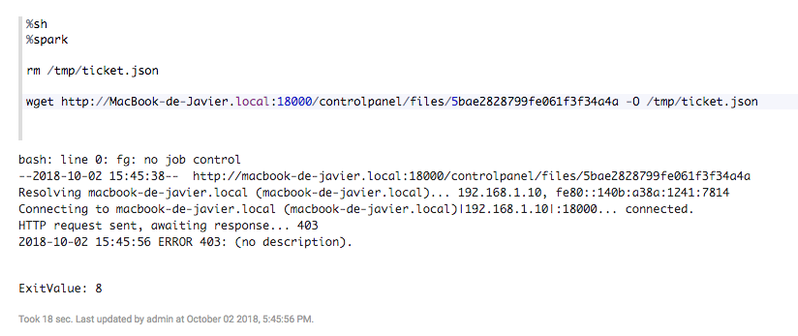
2. The file is not public
Whether the file is shared or not, if the file private, we will need to provide an authentication header:
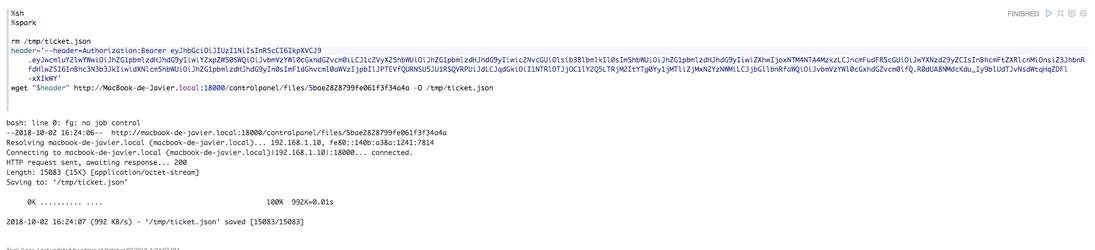
- Authentication: Bearer {token}
If you were previously authenticated via OAuth2 in the platform, then you can use this header:
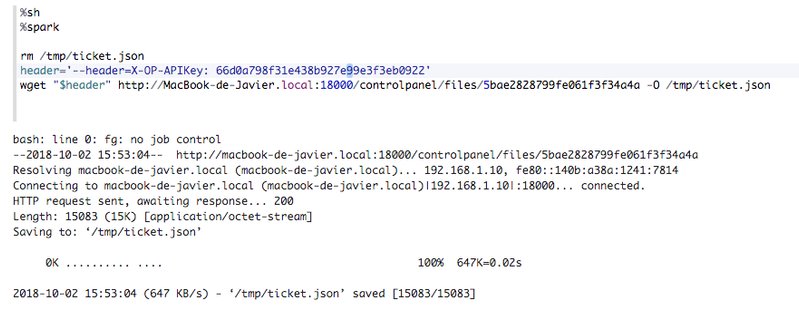
X-OP-APIKey: {user token}
Otherwise, you need to provide a user token header. This token is the same you used for authentication through the API Manager of the platform. You can retrieve it in the path /controlpanel/apimanager/token/list.
Here is the example:
-X-OP-APIKey
-OAuth2
3. Load the file data
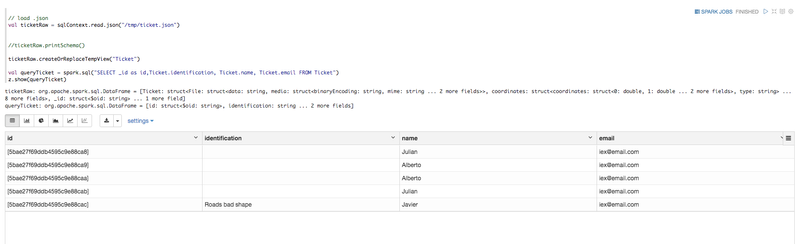
In this case, the file contains instances of the Ontology 'Ticket'.
With Spark, we can read, load and print JSON data.
![]()
(c) 2020 Indra Soluciones Tecnologías de la Información, S.L.U.