¿Qué es una Plataforma Low Code?
Una Plataforma Low Code (LCAP: Low Code Application Platform) es una plataforma que soporta el desarrollo rápido, el despliegue automatizado, la ejecución y la gestión de aplicaciones utilizando abstracciones de programación de alto nivel (Visuales o declarativas).
Estas Plataformas soportan el desarrollo de interfaces de usuario, lógica empresarial y servicios de datos, y mejoran la productividad en comparación con las plataformas de aplicación convencionales.
Un LCAP empresarial debe soportar el desarrollo de aplicaciones empresariales, estas requieren un alto rendimiento, escalabilidad, alta disponibilidad, recuperación antes desastres, seguridad, SLAs, seguimiento del uso de los recursos y soporte técnico del proveedor, y acceso a servicios locales y cloud.
Propuesta de Valor de Onesait Platform como Plataforma Low Code
Onesait Platform se sustenta sobre 4 pilares, uno de ellos alude al desarrollo ágil de soluciones: 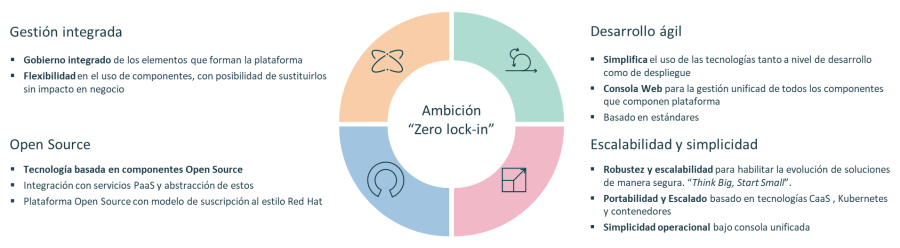
Onesait Platform aporta capacidades en las 4 fases de un proyecto: Arranque (Arquitectura, Provisión,..) , Desarrollo, Despliegue/Operación y Gestión del cambio.
A continuación, veremos las diferencias a la hora de abordar estas fases con un desarrollo tradicional o con un desarrollo basado en Onesait Platform:
Arranque | Desarrollo | Operación | Gestión del cambio | |
Desarrollo tradicional | -Elección y pruebas tecnologías. | -Gran cantidad de código. | -Esfuerzo para desplegar en Entornos. | -Complejidad en entendimiento y evolución de código pasado tiempo. |
Desarrollo | -Provisión automática de entornos. | -Desarrollo visual sobre componentes preparados para usar. | -Despliegue automatizado. | -Desarrollo visual más mantenible. |
Algunas capacidades Low Code de Onesait Platform
En este punto detallaremos algunas de las capacidades que ofrece la Plataforma entendida como Plataforma Low Code, no son todas pero dan una idea del valor añadido que ofrece esta.
Como además Onesait Platform es una Plataforma Data-Centric que permite gestionar el ciclo de vida de la información, habilitando la construcción de aplicaciones con el "dato en el centro" analizaremos estas capacidades en base al tratamiento del dato: 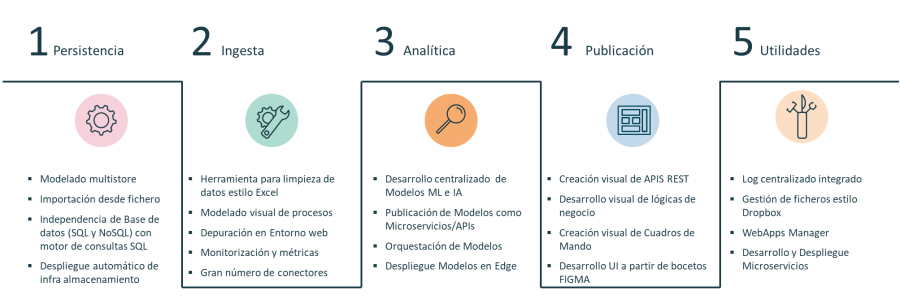
En la Capa de Persistencia
En esta capa la plataforma nos aporta capacidades como el modelado multistore donde la plataforma suministra independencia de la base de datos usada o la importación desde fichero.
Veamos en detalle alguna de estas capacidades.
Modelado multistore
La plataforma permite manejar de forma prácticamente transparente bases de datos de diferente tipo, desde cualquier base de datos relacional con driver JDBC a bases de datos NoSQL como Mongo, Elasticsearch, repositorios Big Data como HIVE y Kudu, ... También es capaz de tratar un API REST o un Digital Twin como otra fuente de datos.
Esta abstracción se hace a través del concepto de ontología, que independiza de la base de datos subyacente, ofreciendo siempre un motor SQL para acceder a esta (incluso cuando usan bases de datos NoSQL como Mongo o Elasticsearch)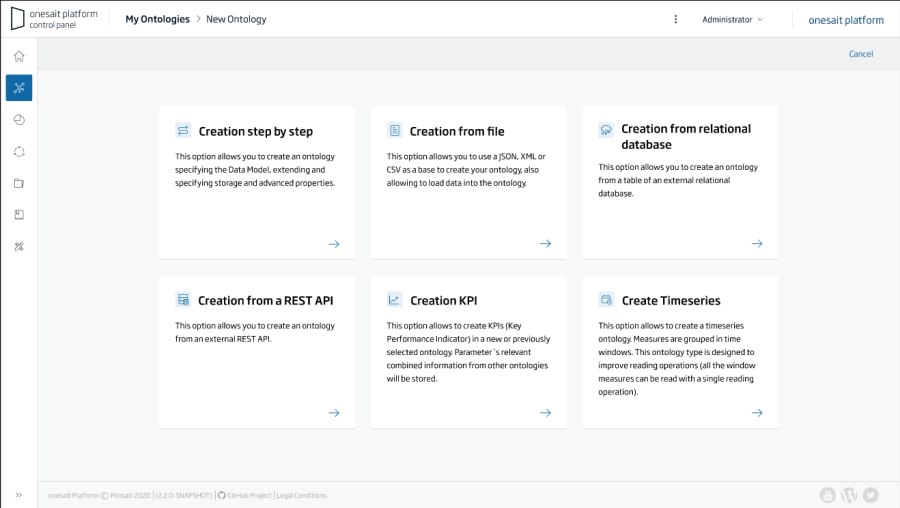
Como puede verse:
- El modelado de las entidades se hace desde el propio Control Panel de la plataforma y cuando creo la entidad en plataforma (las famosas ontologías), esta se encarga de crear las tablas o elementos necesarios en la base de datos seleccionada.
- La plataforma se encarga de provisionar o conectarse con las bases de datos seleccionadas aislando de esta complejidad al equipo de desarrollo.
- La plataforma también permite conectarse a bases de datos ya existentes y crear las ontologías a partir de las tablas existentes.
- La ontología se representa como un JSON-Schema y las instancias de las ontologías son JSONs, esto es independiente del motor de almacenamiento seleccionado, y la plataforma se encarga de convertir hacia y desde este modelo.
Más información sobre el concepto de Ontologías aquí.
Importación desde fichero
La plataforma ofrece una UI para cargar de forma sencilla un fichero en formato JSON, CSV o XML, la plataforma detectará el formato del fichero y generará automáticamente la ontología en el repositorio seleccionado y cargará los datos en esta: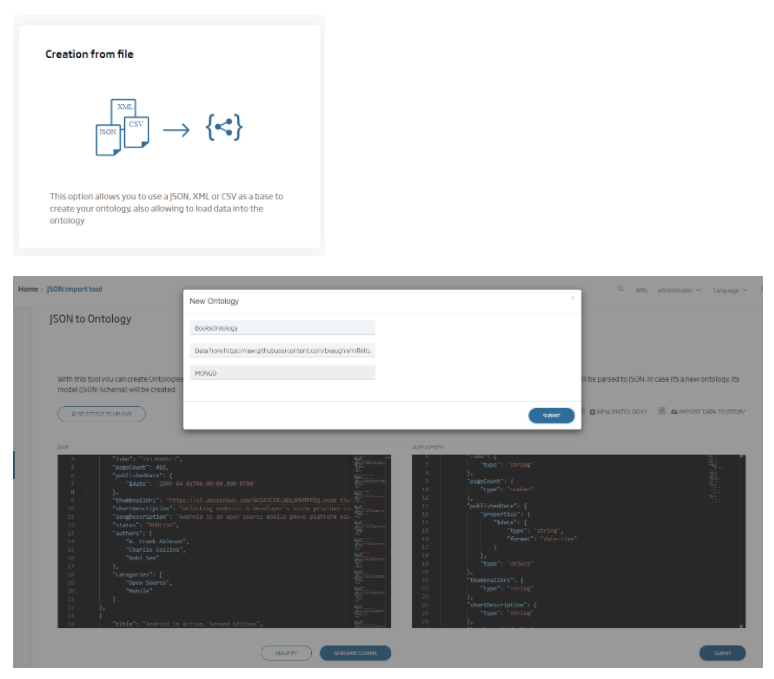
En la capa de Ingesta
En esta capa la plataforma ofrece diversas capacidades, donde destacan el Data Refiner y el Data Flow.
Data Refiner
El objetivo de este componente es "refinar" la información que se carga o que se extrae de plataforma. Para esto la herramienta ofrece un interfaz Excel-like que permite:
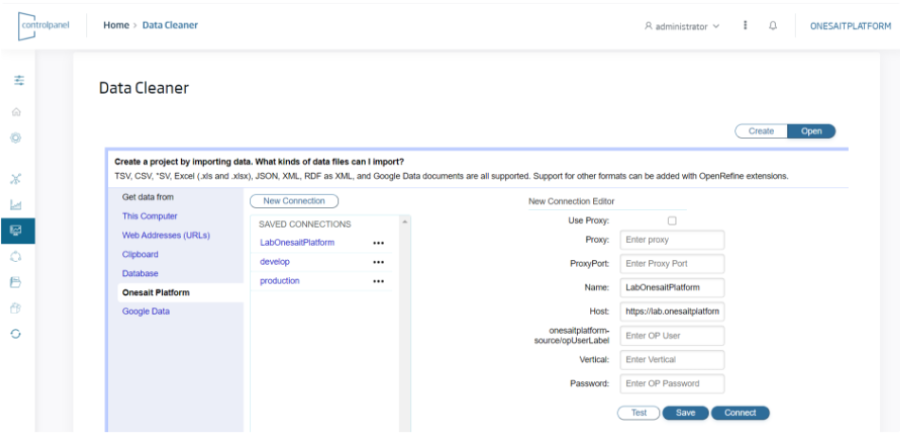
- Que un usuario final cargue desde una UI datos desde diversos lugares, por ejemplo desde su propio PC, desde una URL o bien desde información residente en la propia plataforma.
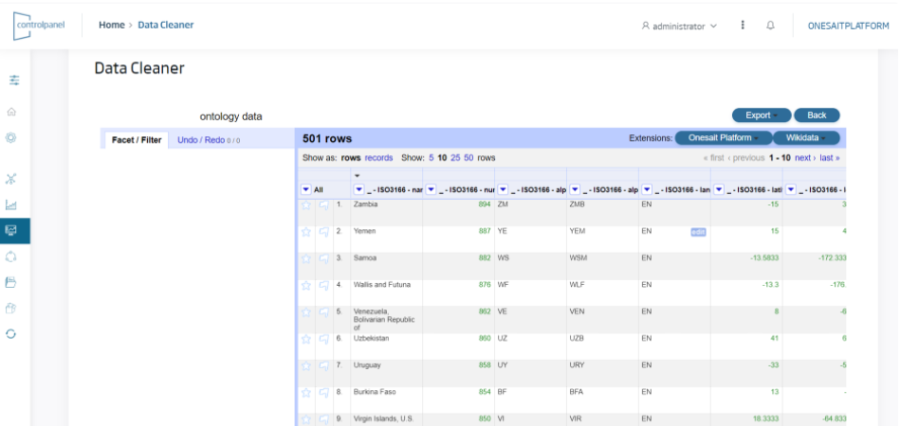
- La herramienta permite cargar datos en los principales formatos, entre ellos Excel, XML, JSON, CSV,…
- El usuario puede trabajar con estos datos con un interfaz "Excel-like" realizar un perfilado de los datos, incluyendo limpieza, mejora, reestructuración o conciliación de estos.
- Los datos "refinados" podrán descargarse como ficheros o bien cargarse en plataforma como Ontología.
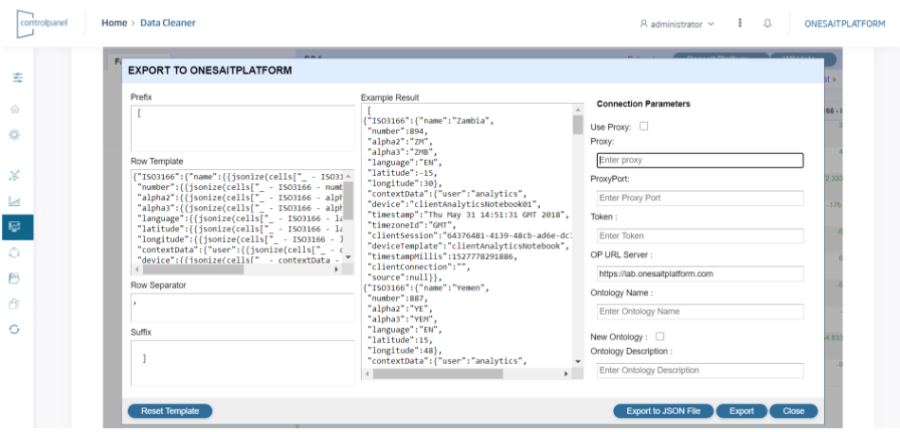
Más información sobre este componente aquí.
Data Flow
Este módulo permite crear y configurar flujos de datos entre orígenes y destinos de forma visual tanto para procesos tipo ETL/ELT como flujos en Streaming, incluyendo en estos flujos transformaciones y procesos de calidad del dato.
Vemos un par de ejemplos:
- Ingesta hacia Hadoop del tail de un fichero con proceso de eliminación de campos:
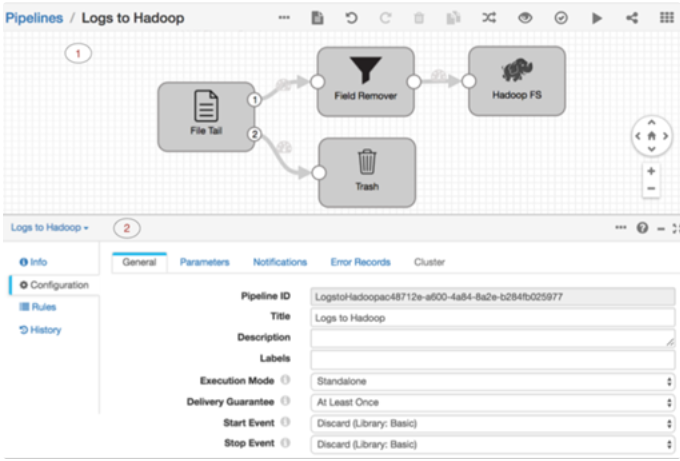
- Ingesta desde un endpoint REST y carga hacia el Semantic DataHub de plataforma con proceso de calidad del dato:
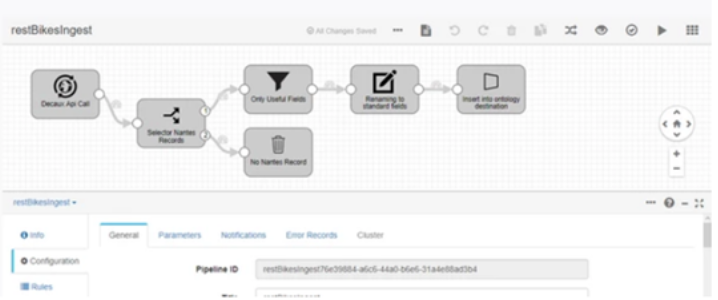
Además de esto:
- Ofrece una gran cantidad de conectores para comunicaciones específicas, tanto de entrada como de salida, además de procesadores (en el Portal del Desarrollador de Plataforma se pueden ver todos los conectores), entre los principales conectores del Dataflow podemos encontrar conectores Big Data con Hadoop, Spark, FTP, Ficheros, Endpoint REST, JDBC, BD NoSQL, Kafka, Servicios Cloud de Azure, AWS, Google,…
- Toda la creación, desarrollo, despliegue y monitorización de los flujos se realiza desde la consola web de la plataforma (Control Panel), por ejemplo aquí se ve un DataFlow en ejecución:
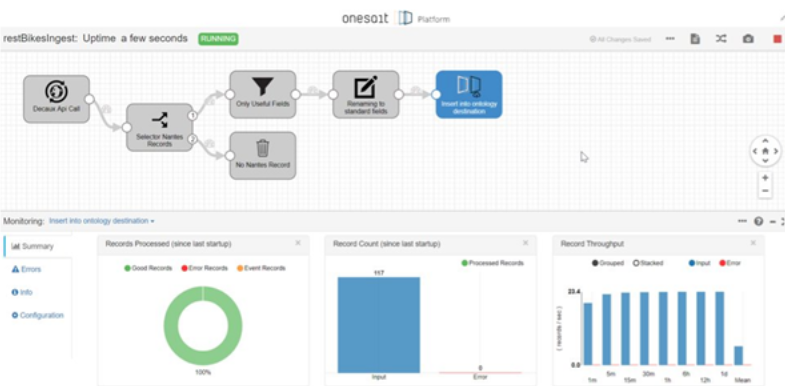
Y aquí en depuración: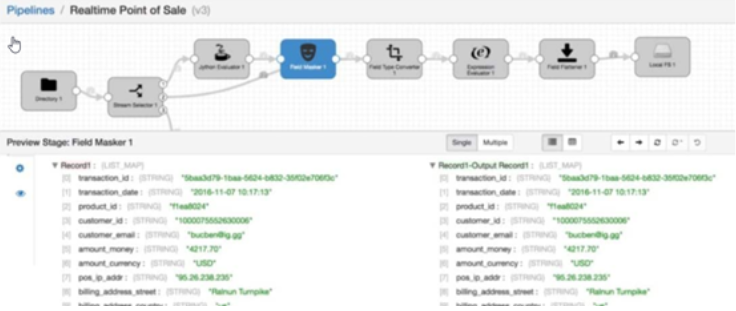
Más información sobre el componente en este enlace.
En la capa de Analítica
En esta capa la plataforma permite la creación de modelos IA desde un entorno centralizado, además de publicar estos modelos como microservicios y APIs. Veamos qué ofrece en esta capa:
Desarrollo centralizado de Modelos ML e IA
El módulo denominado Notebooks provee a los científicos de datos de un entorno web multiusuario en el que elaborar modelos de análisis de la información almacenada en la Plataforma con sus lenguajes favoritos (Python, Spark, R, Tensorflow, Keras, SQL,…) de manera interactiva.
Los notebooks se definen y gestionan desde el propio Control panel de la plataforma, desde donde podemos crear, editar y ejecutar mis modelos (notebooks) desde el propio Control Panel, en la imagen se muestra un ejemplo Python: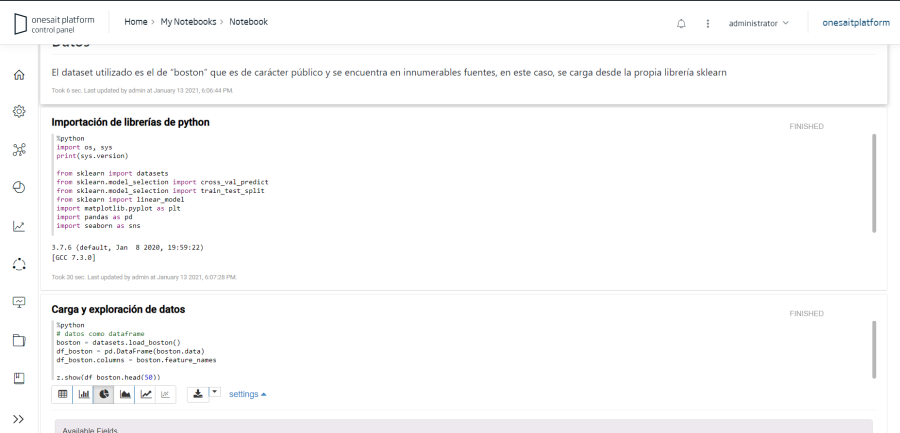
El módulo permite crear algoritmos en diversos lenguajes en función de las necesidades y preferencias del científico de datos, soporta entre otros Python, Spark, R, SparkSQL, SQL, SQL HIVE, Shell,… Se muestra un ejemplo de intercambio de datos entre diferentes lenguajes: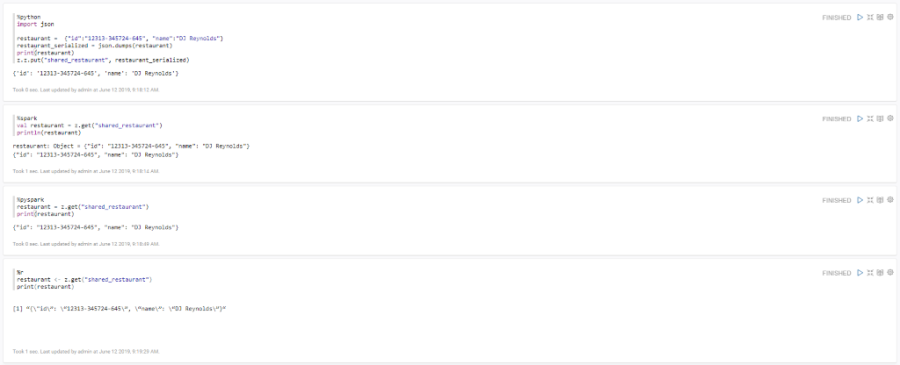
Gracias a las capacidades de servicio de los notebooks por API REST ofrecida por plataforma los notebooks pueden ser orquestados y llamados para ser ejecutados desde el FlowEngine permitiendo un control de ejecución dentro de la lógica de la solución: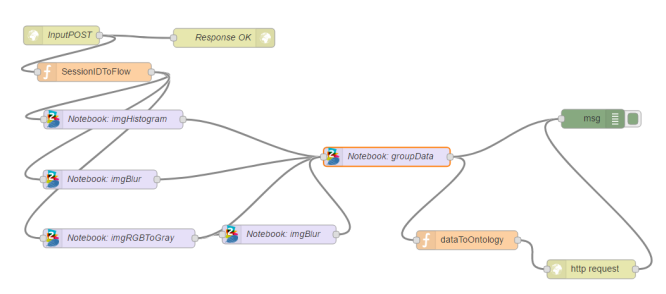
Permite crear visualizaciones de diferentes tipos, incluso añadiendo código HTML vía Angular, lo que nos permite crear visualizaciones muy sofisticadas. Estas visualizaciones pueden agregarse como gadget al motor de dashboards, de esta forma se facilita tanto la analítica de datos como la presentación de resultados, ya sea en informe o expuesto como gadget de plataforma. Un ejemplo de visualización de datos mediante gráficos: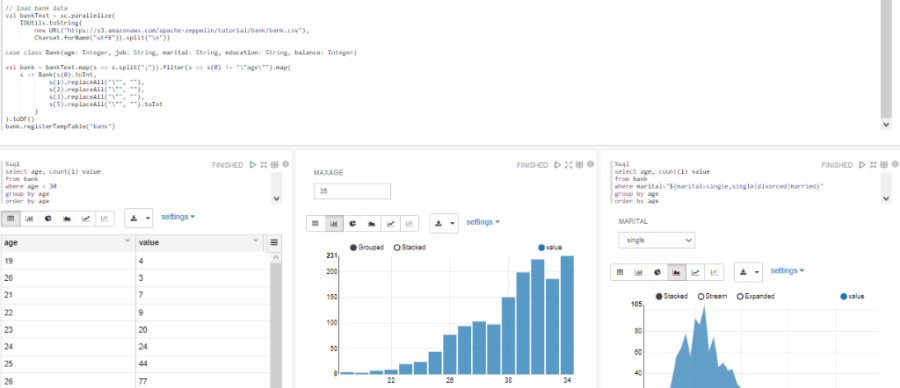
Un ejemplo de visualización de datos geoespaciales sobre cartografía: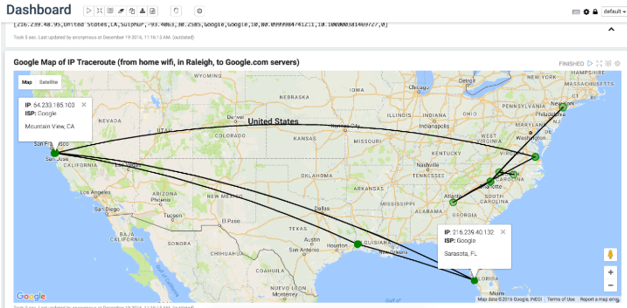
Se puede encontrar más información sobre este módulo en esta sección del Portal del Desarrollador.
Publicación de Notebooks como Microservicios/APIs
La plataforma permite crear desde un notebook un Modelo, indicando los parámetros de entrada y gestionando el resultado de ejecución de cada modelo: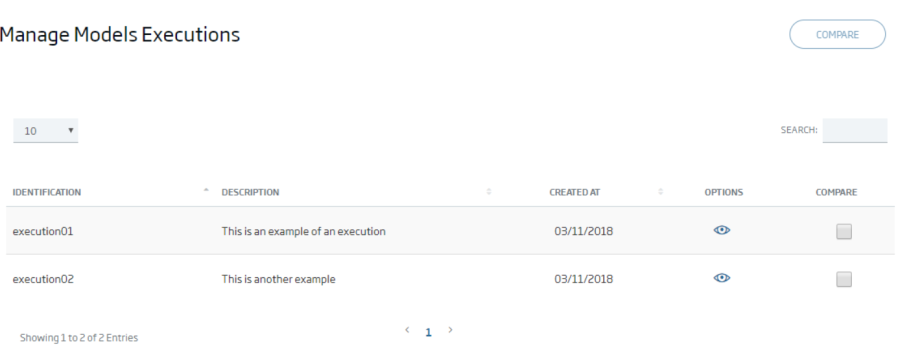
Permitiendo comparar el resultado de un modelo: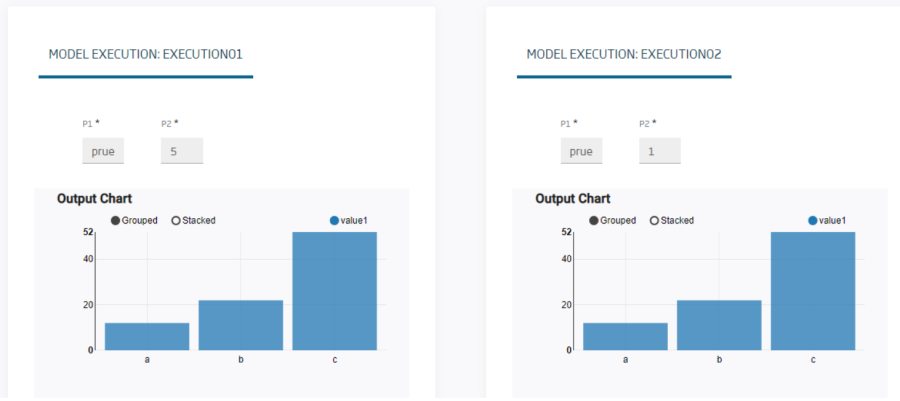
La plataforma también permite publicar un modelo como un microservicio, de modo que la plataforma permite compilarlo, generar la imagen Docker y desplegarlo sobre la infraestructura, es decir la plataforma se encarga de estos pasos: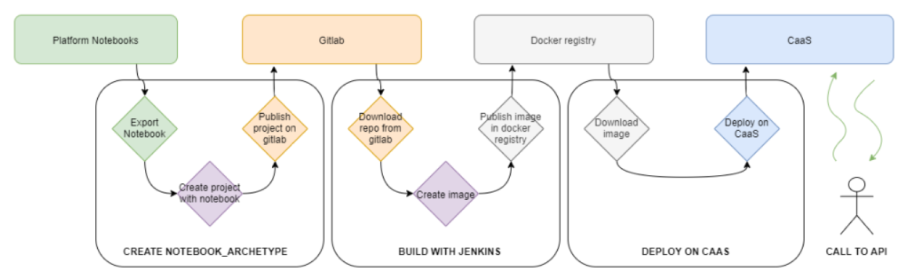
En la capa de Publicación
En esta capa la plataforma ofrece un nutrido conjunto de herramientas, que vamos a pasar a ver:
Desarrollo visual de lógicas de negocio
La plataforma integra un componente denominado Flow Engine, que permite crear flujos de proceso, visualmente orquestando componentes precreados y lógica custom de manera sencilla. 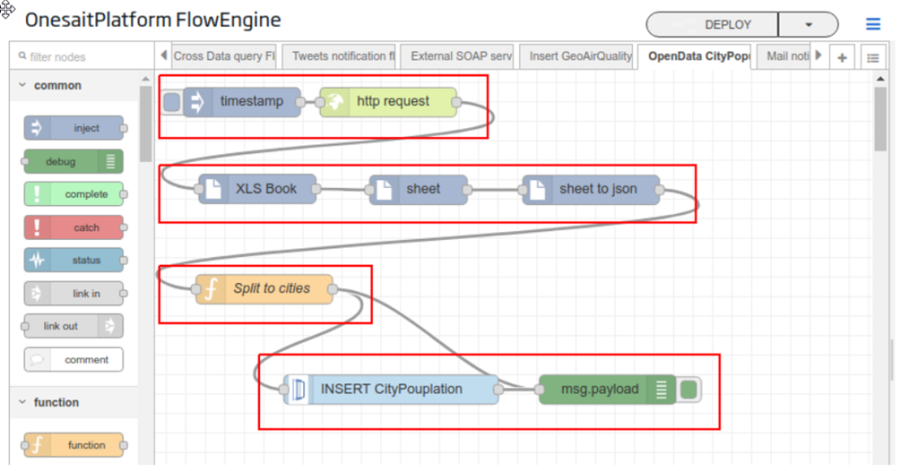
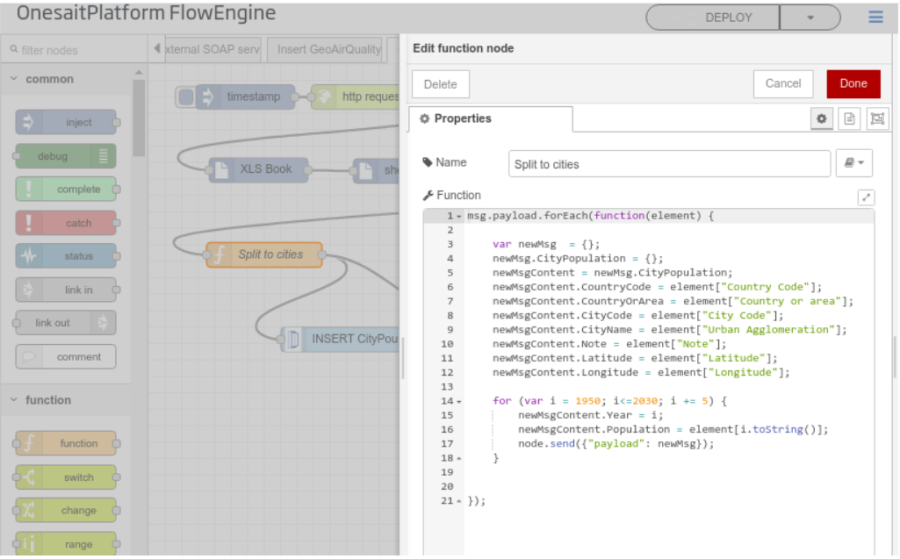
Ofrece un gran número de conectores, que van desde protocolos usados a nivel empresarial como HTTP, Web Services, Kafka, ... a protocolos usados en dispositivos como MODBUS, Profibus, …comunicación con redes sociales...además de componentes para integrar con las capacidades de plataforma.
Este componente además se integra con el resto de componentes de plataforma permitiendo por ejemplo planificar el envío de correos, desencadenar un Flow a la llegada de una ontología, orquestar pipelines de un dataflow, orquestar notebooks,.. 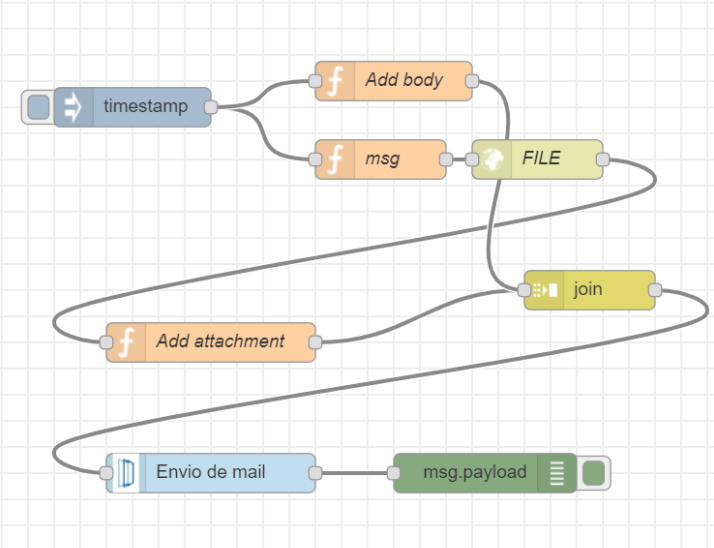
Creación visual de APIS REST
La plataforma integra un API Manager que permite disponibilizar de forma visual y sin programar, APIs REST sobre los elementos gestionados por la plataforma.
Las APIs se definen y gestionan desde el propio Control Panel de la Plataforma: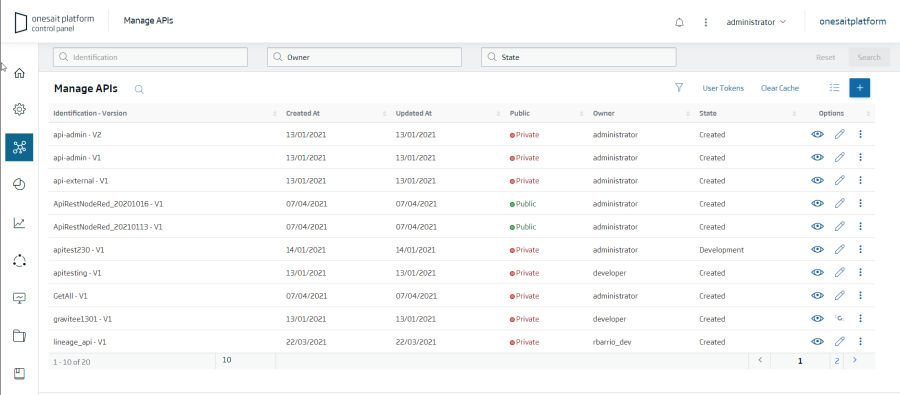
En la imagen se visualiza un API creada sobre una Ontología: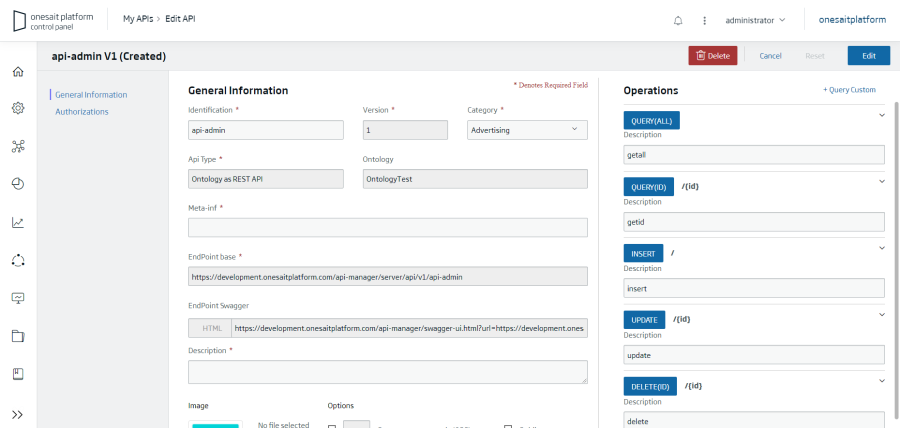
Asociado a cada API se crea el descriptor Open API que permite testar e invocar las Apis para comprobar su funcionamiento.
Además la plataforma permite crear APIs a partir de flujos construidos con el módulo FlowEngine, en la imagen se muestra cómo crear un API REST para enviar correos que encapsula al proveedor real: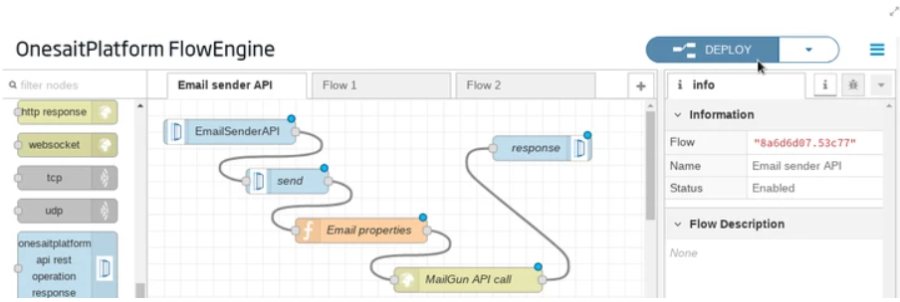
Creación visual de Cuadros de Mando
La plataforma incluye el Dashboard que permite, de forma sencilla, la generación y visualización de potentes cuadros de mando sobre la información gestionada por la plataforma, consumibles desde diferentes tipos de dispositivos y con capacidades analíticas y de data discovery.
Estos dashboards se construyen desde el propio Control Panel de Plataforma y en base a consultas realizadas sobre las entidades de plataforma (datasources) y gadgets pueden construirse completos cuadros de mando.
Vemos como ejemplo esta dashboard creado por nuestro compañero Pedro Moura para mostrar la incidencia del COVID en Portugal (https://lab.onesaitplatform.com/web/covid19pt/#) 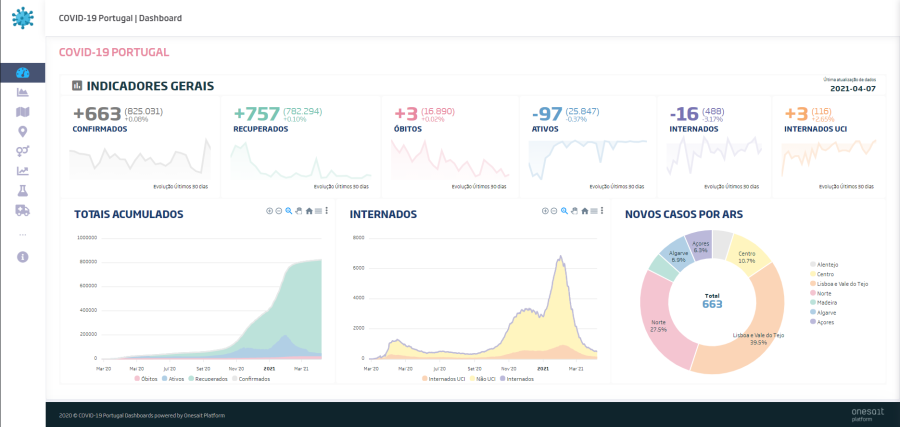
La plataforma ofrece un conjunto de gadgets precreados para usuarios de negocio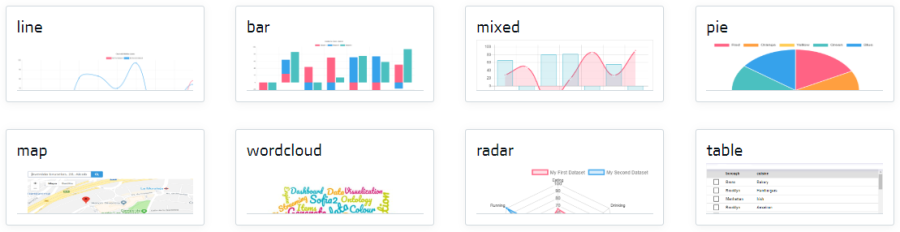
y la capacidad de crear nuevos gadgets a través del concepto de Templates/Plantillas en los que puedo incorporar librerías Javascript y crear mis propios gadgets.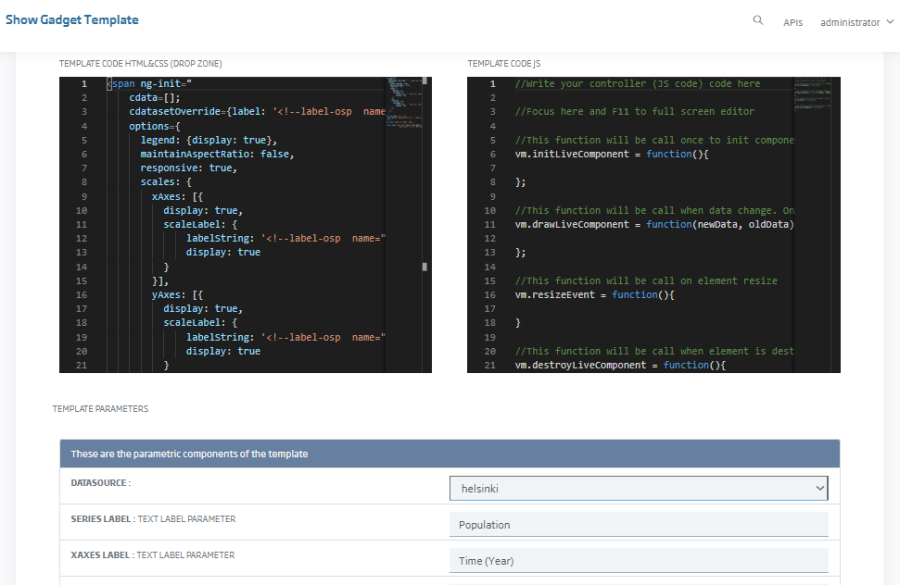
Este módulo permite crear dashboards sobre cualquier dato gestionado como una ontología independiente de su repositorio, y permite la interacción entre gadgets de distinto tipo, de forma que se puede realizar un análisis y drill-down sobre la información de los diferentes gadgets y sus dimensiones de exploración.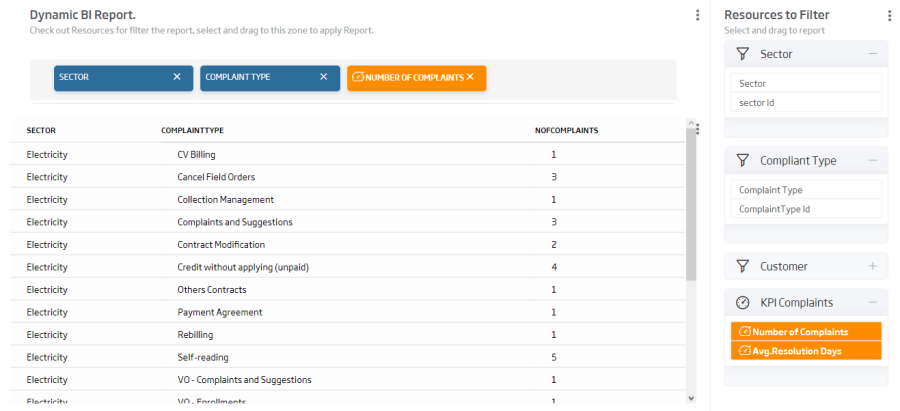
En esta sección del portal del desarrollador se puede encontrar información detallada y ejemplos sobre este componente.
Desarrollo UI a partir de bocetos FIGMA
Para acabar con la capa de publicación hablaremos de una capacidad incorporada recientemente y que permite generar UIs en Vue JS a partir de un diseño FIGMA.
Empezaré por hacer un binding en mi diseño FIGMA a nombres en los elementos visuales y de acción: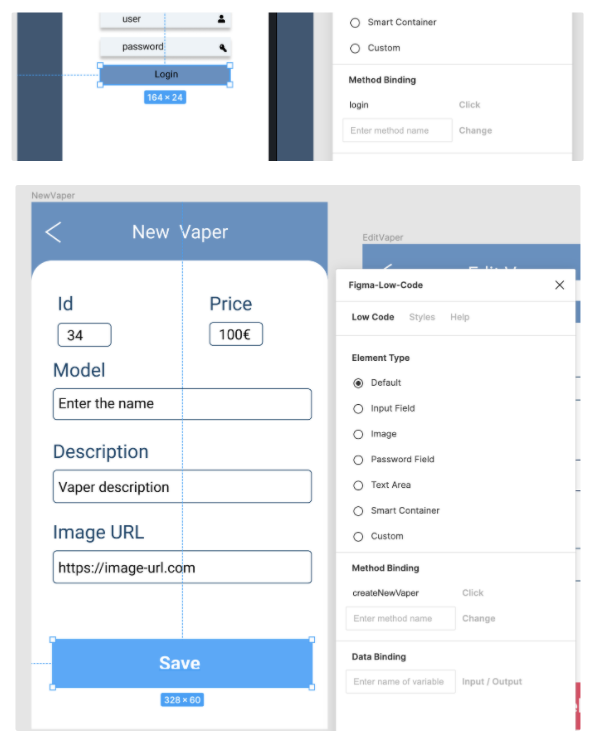
Luego importaré el diseño FIGMA en el Control Panel que reconocerá los bindings y me solicitará información adicional para el mapeo, como los mapeos de los métodos y variables a las APIs definidas en plataforma: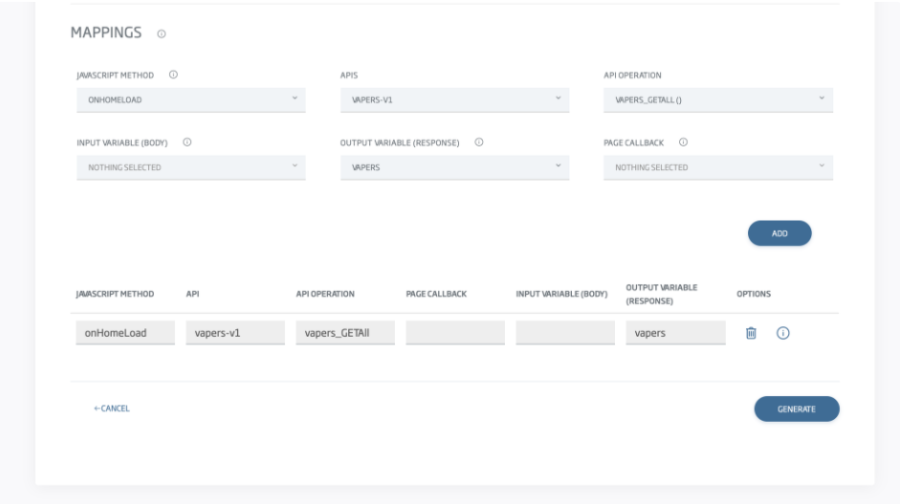
Con esto la plataforma me genera una aplicación Vue.js completamente operativa: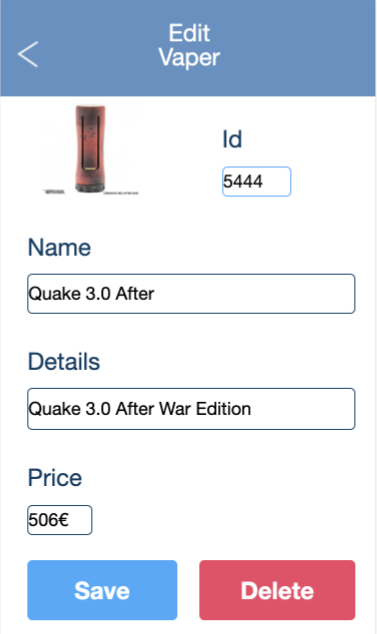
En esta guía se explica en detalle el proceso, también podéis ver el vídeo del ejemplo.
Otras Utilidades
Y para acabar, la plataforma ofrece un conjunto de herramientas que permiten agilizar el desarrollo y centrarnos en el desarrollo de negocio y no en los servicios técnicos necesarios.
El grueso de utilidades pueden encontrarse en esta sección del Portal del Desarrollador, destaquemos algunas de ellas
Log centralizado
La plataforma integra Graylog como solución para centralizar los logs de sus módulos y de otros módulos, Graylog almacena los logs en un Elasticsearch embebido con plataforma y ofrece una UI para explotar la información. 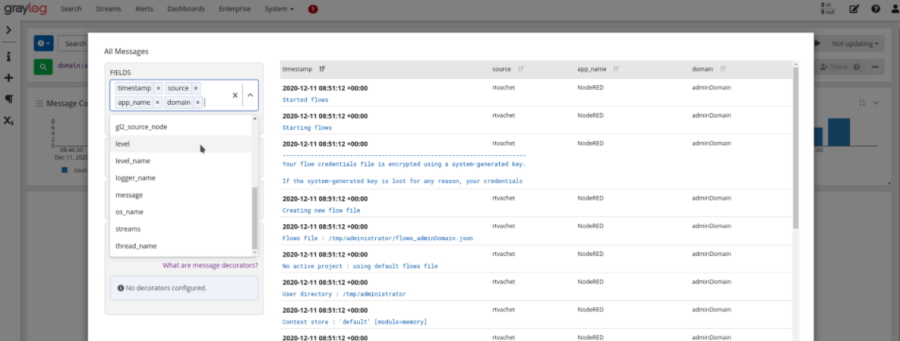
Gestión de ficheros estilo Dropbox
Esta utilidad denominada File Repository permite cargar y compartir todo tipo de ficheros bien a través de la UI o de un API REST. 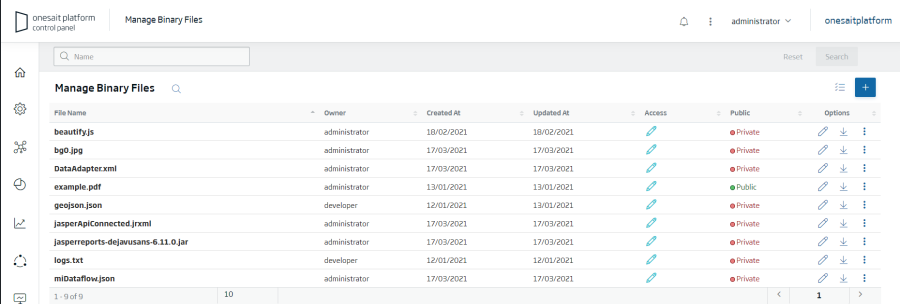
Esta utilidad está integrada con otros componentes como el DataFlow que permite acceder a estos ficheros.
WebApps Manager
Esta utilidad permite desplegar aplicaciones web (una web completa HTML5: HTML, JS, CSS, imágenes,...) desde el propio ControlPanel, de modo que sea la plataforma la que te disponibilice esa web a través de un servidor Web integrado.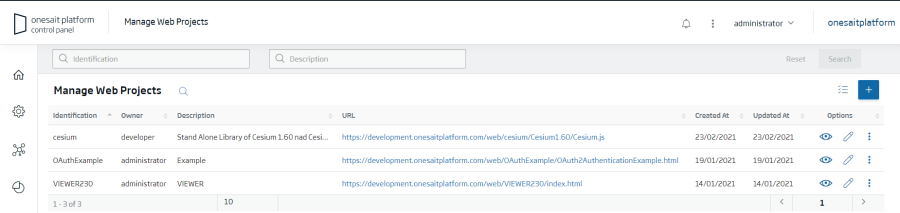
Desarrollo y despliegue Microservicios
La plataforma proporciona una herramienta para crear y administrar el ciclo de vida de aplicaciones y microservicios Spring (y otros) desde el panel de control, siguiendo los estándares del ciclo CI/CD: creación, compilación, ejecución de pruebas, generación de imágenes Docker y despliegue en CaaS
Las funcionalidades que proporciona este ciclo de vida desde la plataforma son:
- Creación de microservicios.
- Descarga de código y desarrollo.
- Compilación del código y generación de imágenes Docker desde Jenkins.
- Despliegue de las imágenes Docker en la plataforma CaaS.
- Actualización de un Microservicio.
En la imagen se muestra la UI desde la cual pueden realizarse de forma sencilla todos estos pasos: