Features | Open Source | Releases | Docs | Try us free | Blog | Product
Historización de ontologías: borrado de instancias antiguas y exportación a archivos
Introducción
Hay una nueva funcionalidad que te permite exportar y eliminar los datos antiguos de una ontología de la base de datos en tiempo real (BDTR). En este tutorial, vamos a explicar cómo configurar una ontología para conseguirlo, y cómo consultar los archivos creados por este proceso.
Configuración de la ontología
Crea/Edita una ontología, y ve a la pestaña de Opciones Avanzadas.
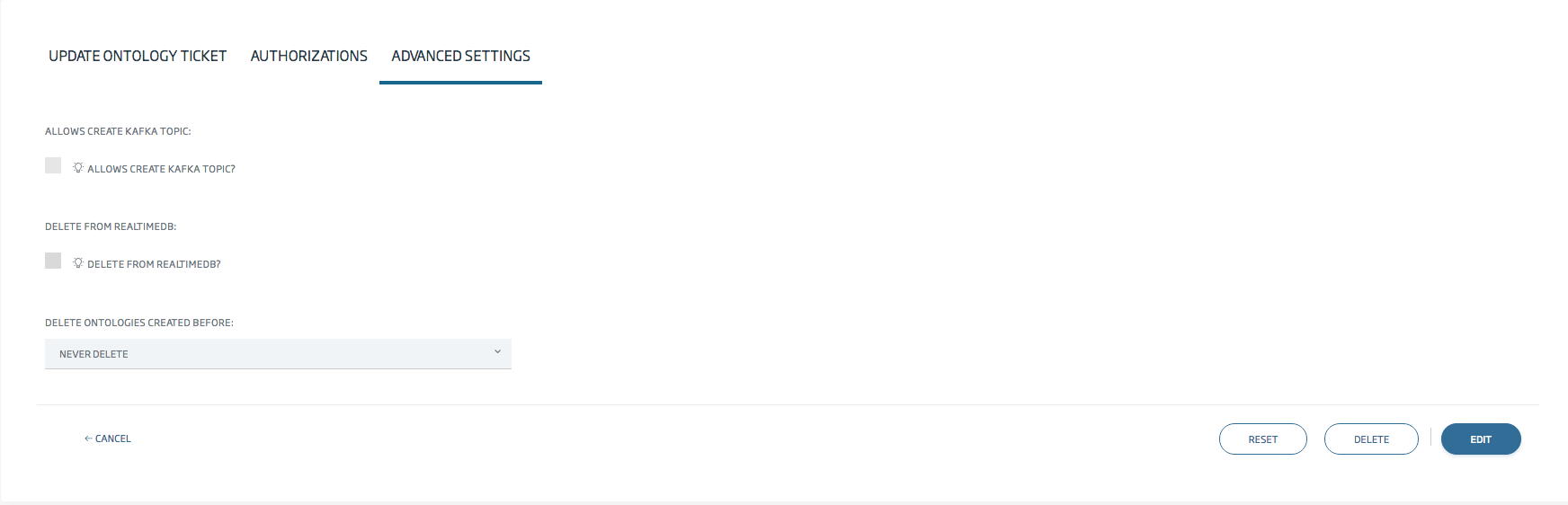
Como puedes ver, hay una opción llamada Borrar de BD Tiempo Real. Si la marcas, tendrás que elegir un umbral de tiempo (1 mes por defecto) a partir del cual se borrarán los datos.
También aparecerá una nueva casilla de verificación cuando marques la opción previa de borrado: ¿Paso a Histórico al borrar los datos?
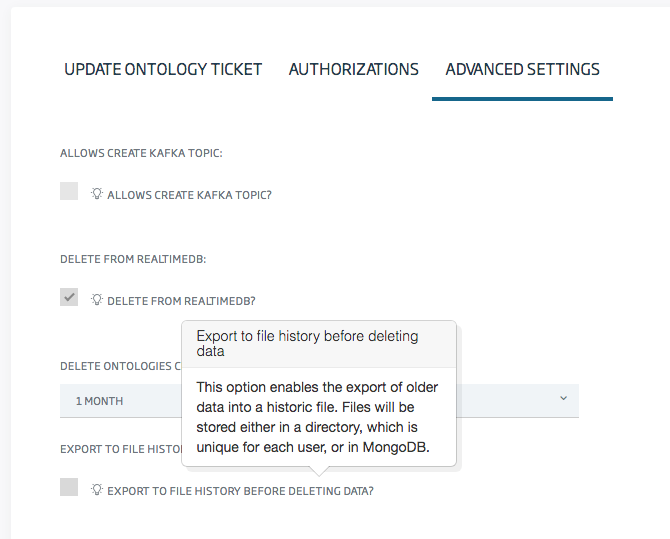
Si marcas esta opción, los datos se exportarán antes de borrarse.
Por último, si lo marcas, tendrás que elegir entre dos modos de almacenamiento: GridFS (Mongo) y archivo de Directorio.
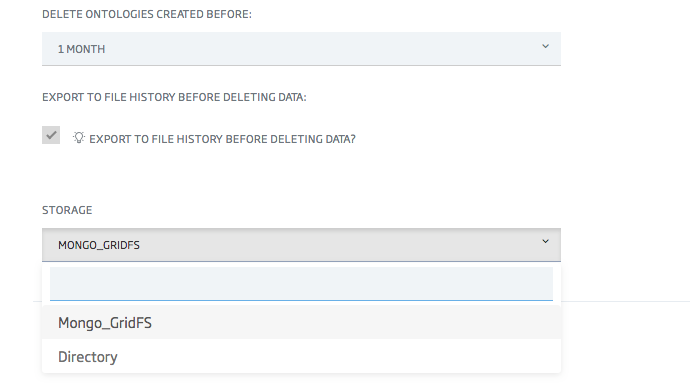
Recomendamos encarecidamente el uso de GridFS, ya que utiliza un sistema de almacenamiento distribuido, mientras que los archivos de directorio no lo hacen.
Recuperando archivos exportados
Hayas elegido GridFS o Directory como almacenamiento, siempre podrás acceder (CRUD) a esos archivos exportados, sea a través de la página del repositorio binario en el panel de control o utilizando el servicio REST expuesto para el repositorio binario.
1. Gestión de archivos binarios del panel de control
Si vas a la ruta /controlpanel/files/list, verás una lista de archivos pertenecientes a tu usuario.
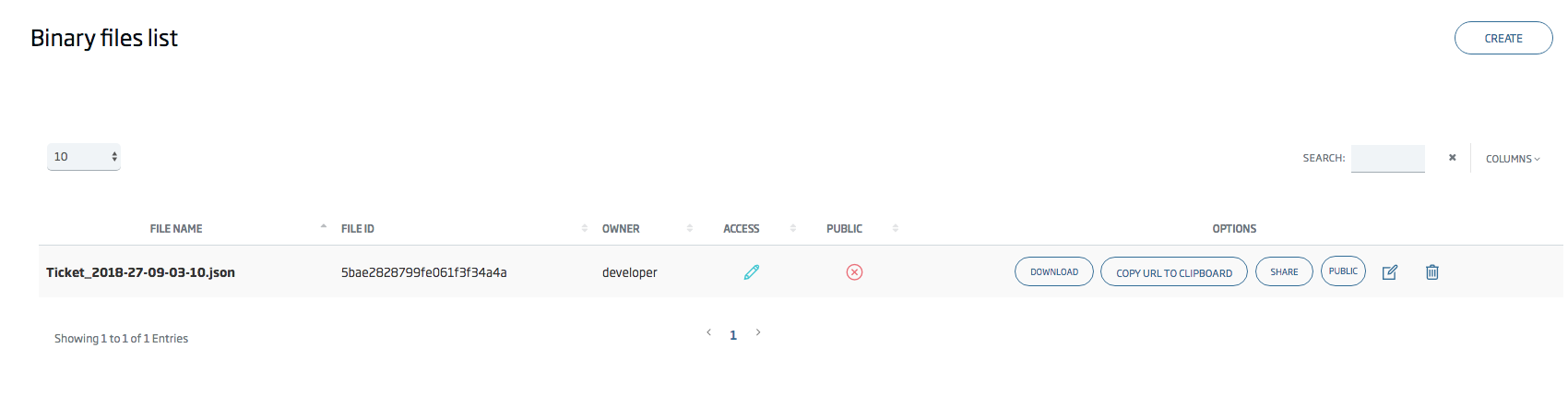
Los archivos que se nombran con el siguiente patrón: (ontología)_(marca de tiempo).json, se convertirán en archivos exportados creados por el proceso de eliminación.
Como se explica en este tutorial, los archivos binarios se pueden compartir con los usuarios de la plataforma, y también se pueden hacer públicos. Si el archivo es público, se puede acceder a él (sólo lectura) sin ningún tipo de autenticación, desde cualquier lugar, por ejemplo, desde un notebook (ejemplo al final de este tutorial).
La opción copiar enlace copia la url externa al portapapeles para acceder al archivo.
2. API REST
Explicado en este post.
Ejemplo de Notebook
En este ejemplo, ilustraremos cómo puedes recuperar un archivo exportado dentro de un Notebook y cargar sus datos.
1. El archivo es público
Si el archivo es público, no necesitas ningún tipo de autenticación: Sólo tienes que hacer una simple request de wget:
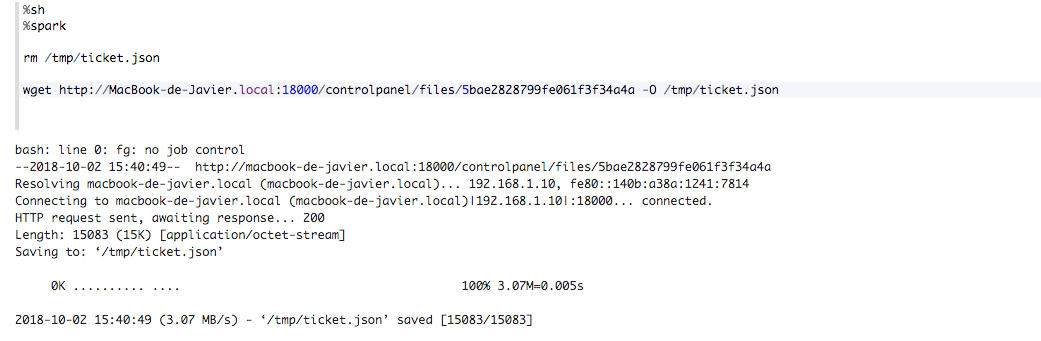
Si el archivo no es público, esto dará una respuesta de error403::
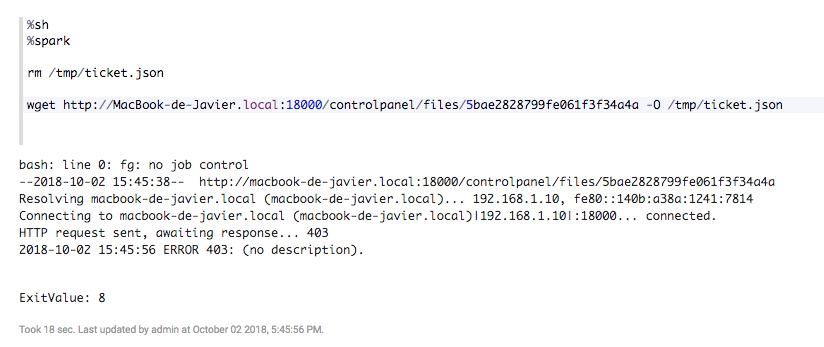
2. El archivo no es público
Tanto si el archivo es compartido como si no, si el archivo es privado, tendrás que proporcionar un encabezado de autenticación:
- Authentication: Bearer {token}
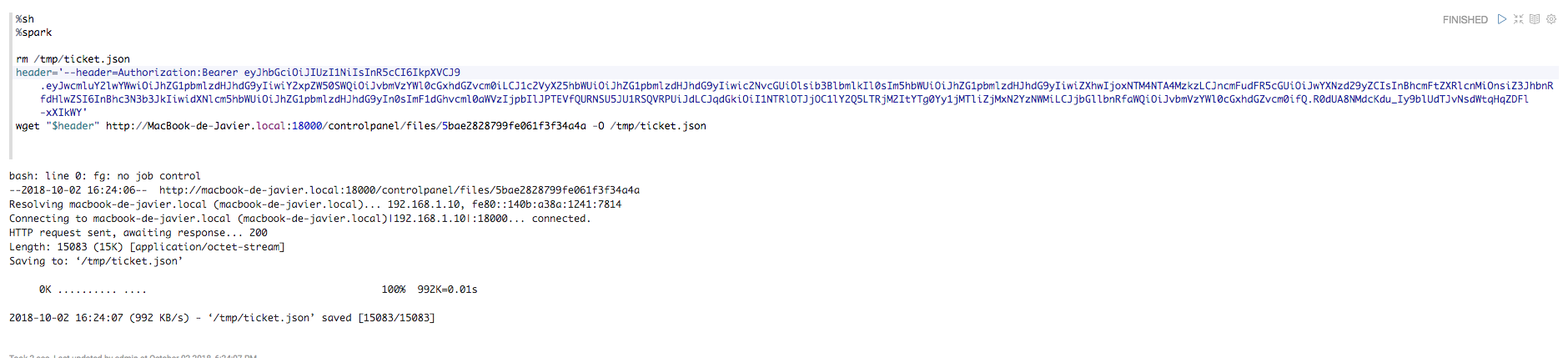
Si ya estabas autenticado en la plataforma a través de OAuth2, entonces puedes usar este encabezado:
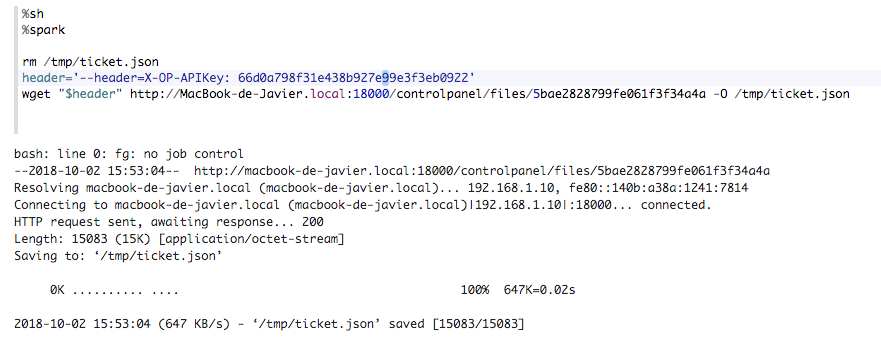
X-OP-APIKey: {token de usuario}
Si no, tendrás proporcionar un encabezado de token de usuario. Este token es el mismo que usaste en la autenticación a través del API Manager de la plataforma. Puedes recuperarlo en la ruta /controlpanel/apimanager/token/list.
Aquí está el ejemplo:
-X-OP-APIKey
-OAuth2
3. Cargar los datos del archivo
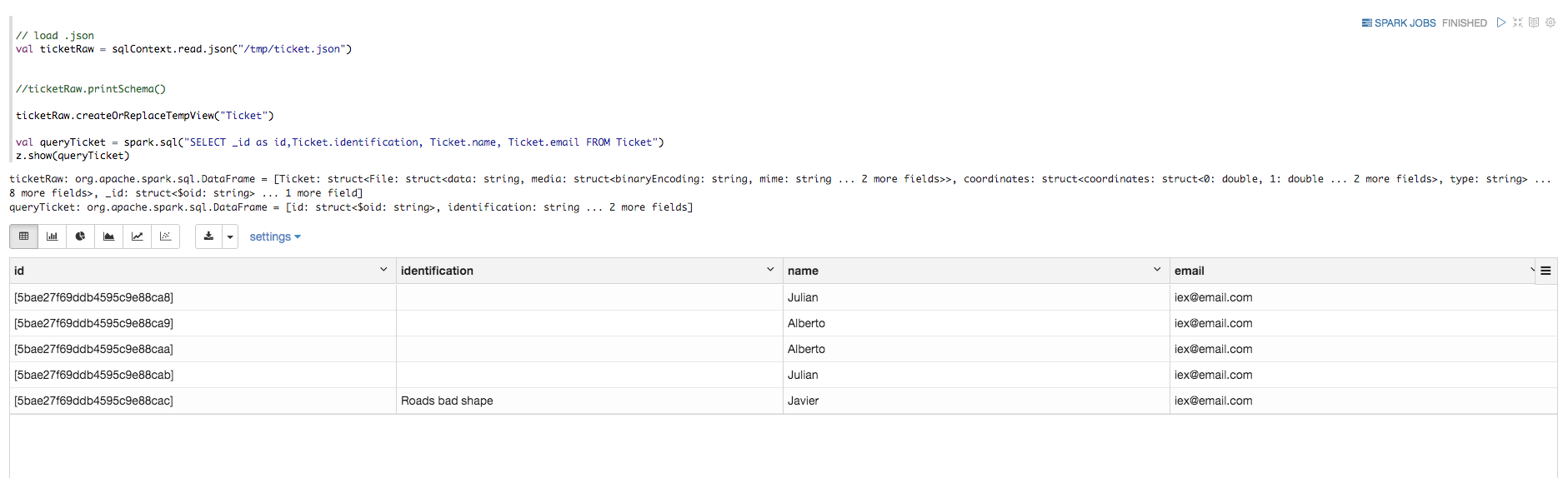
En este caso, el archivo contiene instancias del 'Ticket' de Ontología.
Con Spark, puedes leer, cargar e imprimir los datos de JSON.
![]()
(c) 2020 Indra Soluciones Tecnologías de la Información, S.L.U.